本文旨在结合原文与Peft源码,介绍LoRA
读懂本文需:
熟悉Transformer结构
熟悉Pytorch、Python3
英文出自LoRA 原文,源码出自Peft (删掉部分源码以便阅读)。如本博文存在疏漏,烦请e-mail联系作者
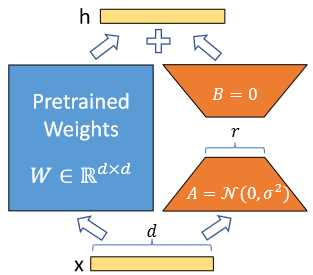
原文提出LoRA(Low-Rank Adaptation)方法,冻结预训练模型权重,将可训练的秩分解矩阵注入到Transformer,大大减少了用于下游任务的可训练参数数量。
We propose Low-Rank Adaptation, or LoRA, which freezes the pretrained model weights and injects trainable rank decomposition matrices into each layer of the Transformer architecture, greatly reducing the number of trainable parameters for downstream tasks
LoRA原理
LoRA相较Prompt或Prefix Tuning,需更改网络结构(保留原网络参数)。它的目标对象是Dense层,翻译原文:
神经网络中的Dense层参数矩阵一般是满秩。研究表明,作用在特定领域(downtask)时,这些参数矩阵具有低的“内在维度”,即使随机映射到较小的子空间,仍可高效推理。微调的目的往往是将神经网络作用于特定任务,LoRA作者假设在Adaptation过程中,权重矩阵更新后也具有较低的“内在秩”。
对预训练模型参数W 0 ∈ R d × k W_0 \in \mathbb{R}^{d\times k} W 0 ∈ R d × k W 0 + Δ W = W 0 + B A \ W_0 + \Delta W = W_0 + BA W 0 + Δ W = W 0 + B A B ∈ R d × r B\in \mathbb{R}^{d \times r} B ∈ R d × r A ∈ R r × k A \in \mathbb{R}^{r \times k} A ∈ R r × k r ≪ min ( d , k ) r\ll\min(d,k) r ≪ min ( d , k ) W 0 W_0 W 0 A A A B B B W 0 W_0 W 0 B A BA B A
引入LoRA前递推公式为:
h = W 0 x h=W_0x
h = W 0 x
引入LoRA后递推公式为:
h = W 0 x + Δ W x = W 0 + B A x h=W_0x+\Delta Wx=W_0 + BAx
h = W 0 x + Δ W x = W 0 + B A x
引入系数α r \frac{\alpha}{r} r α Δ W x \Delta W x Δ W x α \alpha α r r r α \alpha α l r lr l r α \alpha α r r r
We then scale Δ W x \Delta W x Δ W x α r \frac{\alpha}{r} r α α \alpha α r r r
引入α \alpha α
h = W 0 x + α r Δ W x = W 0 + α r B A x h=W_0x+\frac{\alpha}{r}\Delta Wx=W_0 + \frac{\alpha}{r}BAx
h = W 0 x + r α Δ W x = W 0 + r α B A x
新增参数位置
原则上可以将LoRA应用于神经网络中任何权重矩阵子集。
In principle, we can apply LoRA to any subset of weight matrices in a neural network to reduce the number of trainable parameters
以原文默认情况为例:将LoRA仅作用于自注意力相关的参数(Self-Attention)
We limit our study to only adapting the attention weights for downstream tasks and freeze the MLP modules (so they are not trained in downstream tasks) both for simplicity and parameter-efficiency.
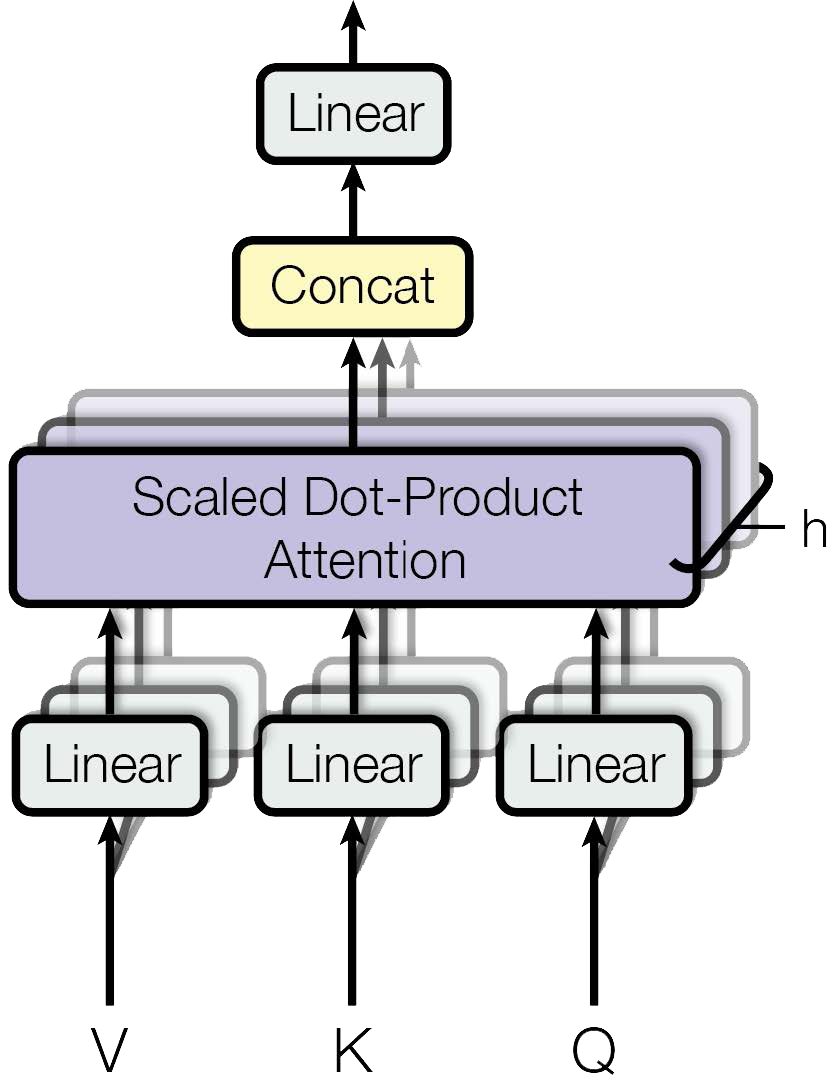
在Peft的实现中,LoRA作用于线性层和一维卷积层(linear/Conv1D)。本博文LoRA作用于Self-Attention层的query、key、value的映射权重矩阵(query_key_value),即Transformer 原文中的W q , W k , W v W_q,W_k,W_v W q , W k , W v
Transformer/Bloomz 将W q , W k , W v W_q,W_k,W_v W q , W k , W v A t t e n t i o n Attention A tt e n t i o n
引入LoRA时不必单独为W q , W k , W v W_q,W_k,W_v W q , W k , W v
参数插入方式
1 2 3
Linear:它不是Pytorch的Linear,而是Peft重写的带LoRA旁路的Lineartarget:被替换的神经网络层,此处为nn.Linearkwargs:包含LoRA的参数:内在秩r r r α \alpha α
Linear层的初始化过程如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class Linear (nn.Module, LoraLayer):def __init__ ( self, base_layer, r: int = 0 , lora_alpha: int = 1 , lora_dropout: float = 0.0 , **kwargs, ) -> None :super ().__init__()
初始化新Linear的重要步骤有两个
LoraLayer.__init__(self, base_layer, **kwargs):将原先的layer作为该Linear对象的base_layer
self.update_layer(adapter_name, r, lora_alpha, lora_dropout, init_lora_weights, use_rslora):设置LoraLayer的LoRA参数
① LoraLayer层的初始化方式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class LoraLayer (BaseTunerLayer ):def __init__ (self, base_layer: nn.Module, **kwargs ) -> None :if isinstance (base_layer, nn.Linear):
self.base_layer = base_layer:将原先的Dense层作为新Linear的线性层in_features, out_features = base_layer.in_features, base_layer.out_features:获取原先Dense层的输入维度和输出维度,存储用于后续的LoRA参数矩阵B B B A A A
② LoRA矩阵的分配及参数设置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class LoraLayer (BaseTunerLayer ):def update_layer (self, adapter_name, r, lora_alpha, lora_dropout, init_lora_weights, use_rslora ):False )False )if use_rslora:else :if init_lora_weights == "loftq" :elif init_lora_weights:
展示A ∈ R i n _ f e a t u r e s × r A\in \mathbb{R}^{in\_features \times r} A ∈ R in _ f e a t u res × r self.lora_A)及B ∈ R r × o u t _ f e a t u r e s B\in \mathbb{R}^{r \times out\_features} B ∈ R r × o u t _ f e a t u res self.lora_B)
self.reset_lora_parameters(adapter_name, init_lora_weights)用于W A , W B W_A,W_B W A , W B self.scaling[adapter_name] = lora_alpha / r:根据α \alpha α r r r
③ LoRA矩阵的默认初始化方式
1 2 3 4 5 6 7 8 class LoraLayer (BaseTunerLayer ):def reset_lora_parameters (self, adapter_name, init_lora_weights ):if adapter_name in self.lora_embedding_A.keys():
nn.init.zeros_(self.lora_embedding_A[adapter_name]):A ∈ R i n _ f e a t u r e s × r A\in \mathbb{R}^{in\_features \times r} A ∈ R in _ f e a t u res × r self.lora_A)初始为0nn.init.normal_(self.lora_embedding_B[adapter_name]):B ∈ R r × o u t _ f e a t u r e s B\in \mathbb{R}^{r \times out\_features} B ∈ R r × o u t _ f e a t u res
默认初始化方式和LoRA原文正好相反(见图1),原文”使用随机高斯分布初始化A A A B B B Δ W = B A \Delta W=BA Δ W = B A
We use a random Gaussian initialization for A A A B B B Δ W = B A \Delta W=BA Δ W = B A
前向传播方式
前向传播源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 class Linear (nn.Module, LoraLayer):def forward (self, x: torch.Tensor, *args: Any , **kwargs: Any ) -> torch.Tensor:if self.disable_adapters:if self.merged:elif self.merged:else :for active_adapter in self.active_adapters:if active_adapter not in self.lora_A.keys():continue return result
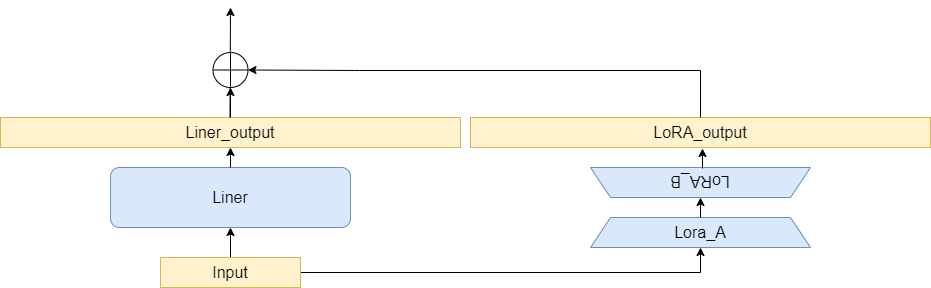
关注源码中的两行:
result = self.base_layer(x, *args, **kwargs) :原线性层仍执行前向传播流程result += lora_B(lora_A(dropout(x))) * scaling:和公式保持一致
写在后面
LoRA作者强调不会引入推理时延:只需要用W ′ = W + B A W^{\prime}=W+BA W ′ = W + B A W W W W ′ W^{\prime} W ′ W W W W ′ W^{\prime} W ′ W W W self.merged控制),B A x BAx B A x
另一点,作者提到一些微调方法会减少模型的有效sequnece length,这一点博主会补充在《prompt tuning介绍》一文。
reduce the model’s usable sequence length
参考
Attention Is All You Need LoRA: Low-Rank Adaptation of Large Language Models huggingface/transformers huggingface/peft